Large Language Models for Automatic Code Repair
Introduction
Large Language Models (LLMs) are transforming software development by excelling in tasks such as generating new code. However, their performance with complex legacy codebases has limitations. To bridge this gap, we adopt the ScalarLM unified framework to train state-of-the-art pre-trained models (e.g., LLaMA) using our curated bug report dataset.
Integrating LLMs into the code repair pipeline boosts productivity, minimizes errors, and enhances security by automating the resolution of vulnerabilities. In the high-stakes world of Linux kernel development—where reliability and security are paramount—LLMs offer an efficient solution for identifying and fixing critical issues. This post explores their application in Linux code repair through a practical case study.
Why Automated Code Repair is Critical for Linux Development
Linux development faces unique challenges due to its scale, reliability demands, and open-source nature:
1. Scale and Complexity
The Linux kernel comprises millions of lines of code, making manual bug identification daunting.
2. Reliability and Security
As the backbone of critical infrastructure, Linux must maintain impeccable reliability. Vulnerabilities can lead to catastrophic failures.
3. Community Contributions
With a global contributor base, code quality can vary significantly, making it difficult to maintain uniform coding standards.
Automated code repair tackles these challenges by detecting bugs proactively, enforcing consistent quality standards, and enabling rapid vulnerability patching—all while reducing the manual workload for developers.
Case Study: Fixing Buffer Overflow Errors with LLMs
Understanding Buffer Overflow
Buffer overflows occur when more data is written to a memory buffer than it can hold, causing adjacent memory to be overwritten. These vulnerabilities, common in languages like C, pose severe security risks:
- Code Execution: Malicious code injection.
- System Crashes: Kernel-level disruptions.
- Instability: Threats to system reliability.
Workflow Overview
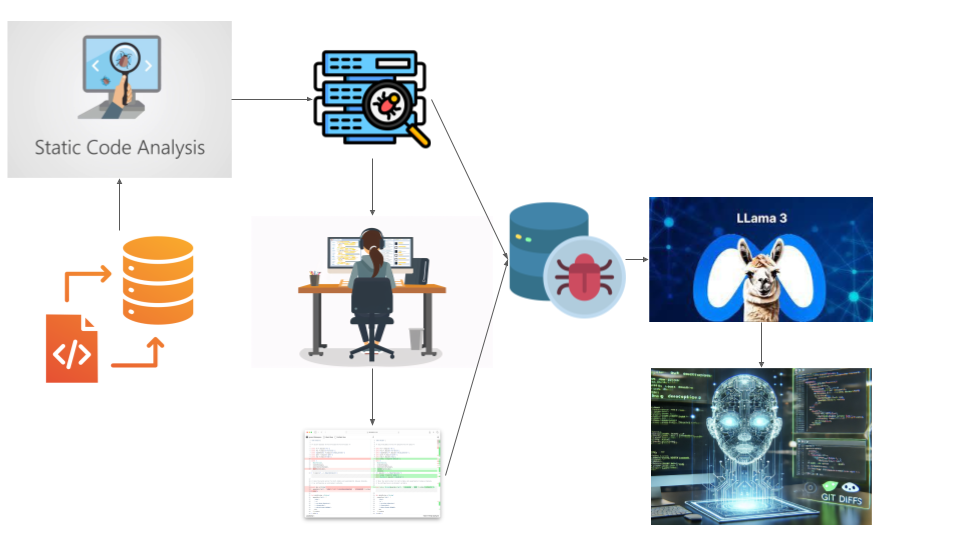
1. Bug Detection
Static code analysis tools identify potential issues. Bug reports generated by static code analysis tools typically include details such as the source file name, bug type, line number, description of the issue, and a suggested fix. Here’s an example:
CID: 1845632
Type: Buffer overflow
Category: BUFFER_OVERFLOW
Classification: Bad use of string function
Severity: High
Certainty: Absolute
Status: New
Function: cxl_mem_create_range_info
File: drivers/cxl/core/mem.c
Line: 723
Issue:
Unbounded sprintf can cause buffer overflow. The code uses sprintf() without size limits to write into buffer 'range_id', which could lead to buffer overflow if the formatted string exceeds the buffer size.
Description:
The function cxl_mem_create_range_info() uses sprintf() to format a memory range identifier into a string buffer 'range_id' without checking if the resulting string will fit in the destination buffer. This could lead to a buffer overflow if the range address and size generate a string longer than the size of range_id.
Use snprintf instead
2. Training Data Curation
Experts pair bug reports with manual fixes (e.g., git diffs) to serve as a training dataset for a Large Language Model (LLM). For example:
diff --git a/drivers/cxl/core/mem.c b/drivers/cxl/core/mem.c
index 9af4721c5e32..b7d45890c453 100644
--- a/drivers/cxl/core/mem.c
+++ b/drivers/cxl/core/mem.c
@@ -720,7 +720,7 @@ static int cxl_mem_create_range_info(struct cxl_dev_state *cxlds)
struct cxl_memdev *cxlmd = to_cxl_memdev(cxlds->dev);
char range_id[32];
- sprintf(range_id, "0x%llx-%llx", range->start, range->size);
+ snprintf(range_id, sizeof(range_id), "0x%llx-%llx", range->start, range->size);
cxlds->range_id = kstrdup(range_id, GFP_KERNEL);
if (!cxlds->range_id)
return -ENOMEM;
Using just a dozen highly curated samples, we train a pre-trained model on this task. When evaluated on a held-out test set, the diffs generated by the trained model demonstrated strong quality and alignment with expert-created fixes.
3. Model Fine-Tuning
The Cray-LM framework fine-tunes a pre-trained Llama model using a dataset formatted as JSON lines. Each sample includes fields such as:
['bug_report_path', 'bug_report_text', 'diff_path', 'diff_text', 'source_code_path', 'line_number', 'code']
This input is preprocessed and a few lines above and below the offending line_number are used as additional context. This information is then fed to the train the model.
import masint
import jsonlines
# Retrieve source code snippet with line numbers
def get_source_code(data, before_lines=5, after_lines=5):
lines = data["code"].split("\n")
start_line = max(0, data["line_number"] - before_lines)
end_line = min(len(lines), data["line_number"] + after_lines)
return "\n".join(lines[start_line:end_line])
# Prepare training data
def get_data(training_data_file, dataset_size=1000):
with jsonlines.open(training_data_file) as reader:
raw_data = list(reader)
return [
{
"input": prompt_template.format(
source_code_path=entry["source_code_path"],
line_number=entry["line_number"],
code=get_source_code(entry),
bug_report_text=entry["bug_report_text"]
),
"output": entry["diff_text"]
}
for entry in raw_data[:dataset_size]
]
# Main function
def main():
data = get_data(training_data_file=args.input)
llm = masint.SupermassiveIntelligence()
llm.train(data, train_args={"max_steps": 20, "learning_rate": 3e-3})
4. Automated Fix Generation
The fine-tuned LLM generates code patches based on new bug reports.
import jsonlines
import masint
def load_data(eval_file_path):
with jsonlines.open(eval_file_path) as reader:
return list(reader)
def get_source_code(data, before_lines=5, after_lines=5):
lines = data["code"].split("\n")
start_line = max(0, data["line_number"] - before_lines)
end_line = min(len(lines), data["line_number"] + after_lines)
return "\n".join(lines[start_line:end_line])
def get_dataset(data):
return [
prompt_template.format(
source_code_path=entry["source_code_path"],
line_number=entry["line_number"],
code=get_source_code(entry),
bug_report_text=entry["bug_report_text"]
)
for entry in data
]
def main():
data = load_data(eval_file_path=args.input)
dataset = get_dataset(data)
llm = masint.SupermassiveIntelligence()
for entry in dataset:
results = llm.generate(prompts=[entry])
print(f"\n{results}")
5. Validation
Generated fixes are manually compared against reference diffs to validate accuracy and alignment with coding standards. This enhanced workflow demonstrates how LLMs can be leveraged to automate bug detection and repair, reducing both development time and security risks.
Limitations and Challenges
While the results are promising, there are notable limitations and challenges:
1. Limited Bug Diversity
The effectiveness of the model heavily depends on the diversity of bug types in the training set. For example, if a bug type is underrepresented, the model may struggle to generalize fixes for similar issues.
2. Context Limitations
To provide accurate fixes, the necessary context for the bug must be small and contained within a single source file. Handling bugs that span multiple files or require a broader understanding of the codebase is beyond the current model’s capabilities.
3. Manual Data Curation
Creating the bug report and fix dataset requires significant manual effort by experts deeply familiar with the codebase. This process is time-intensive and limits scalability.
Conclusion
This study demonstrates the potential of fine-tuning LLMs on small, curated datasets for automated code repair. The model consistently produces high-quality fixes on test data, highlighting the synergy between expert domain knowledge and machine learning. However, addressing challenges such as bug diversity, context limitations, and dataset scalability is crucial for further advancement.
Future Work
1. Broaden Dataset Diversity
Collaborate with domain experts to develop a richer, more diverse training dataset that better represents real-world bugs.
2. Expand Contextual Understanding
Research methods for incorporating multi-file context and broader codebase insights to handle more complex bugs.
3. Automate Data Generation
Investigate semi-automated approaches to streamline dataset creation, including tools to identify bugs and propose preliminary fixes.
By tackling these challenges, we can improve the robustness and applicability of LLM-based code repair systems, enabling their seamless integration into software development workflows.
Have thoughts or experiences with using LLMs for code repair? Send us a message to get involved!